A new study by researchers from Cohere Labs, MIT, Stanford, and others is raising red flags about LMArena, the popular crowdsourced AI benchmark. According to the report, the platform may be giving unfair advantages to major tech companies—skewing results and distorting public perception.
The Details:
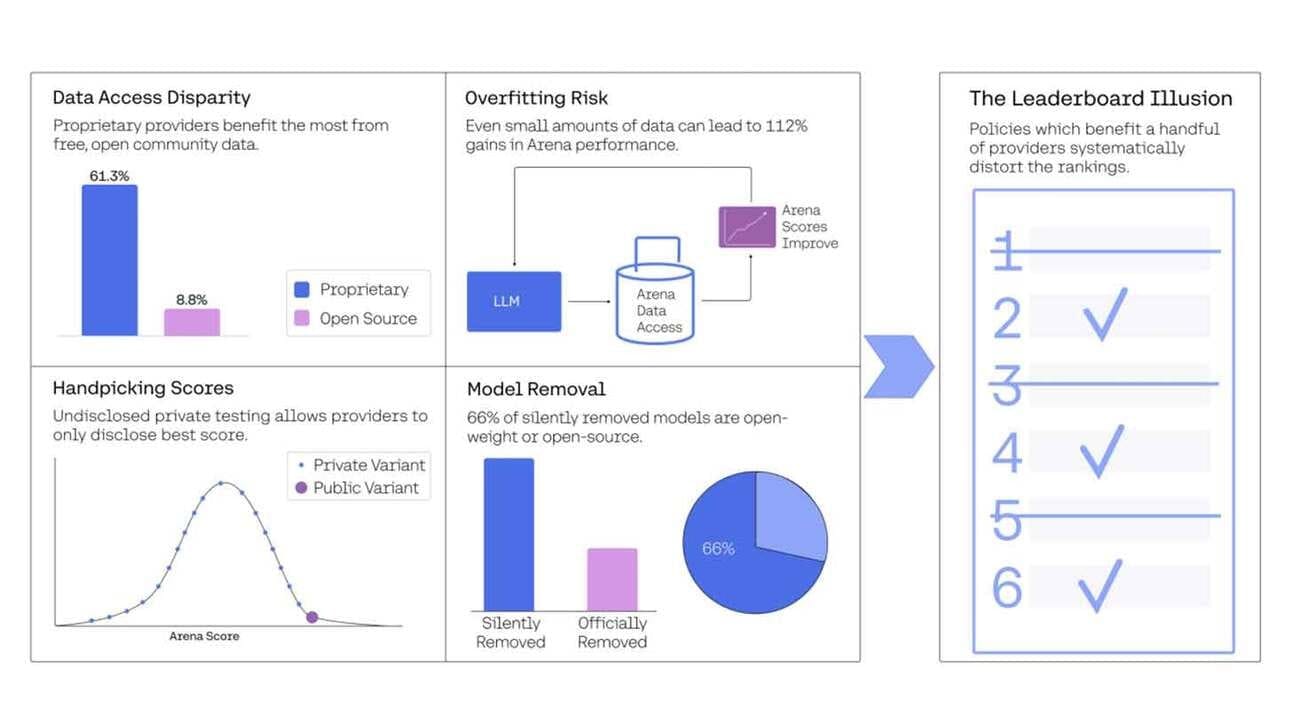
- Private Playtesting: The study claims companies like Meta, Google, and OpenAI quietly test multiple versions of their models on LMArena—only publishing the top-performing ones.
- Sampling Bias: Over 60% of user interactions were with models from Google and OpenAI, while smaller labs and open-source models were underrepresented.
- Overfitting Advantage: Researchers found that having access to Arena data significantly boosts performance on Arena-specific tasks—suggesting models may be tuned to the test, not generally better.
- Silent Deletions: The study notes that 205 models have been removed from the platform without public notice. Open-source models were deprecated more frequently.
Why It Matters:
LMArena has pushed back, saying the rankings reflect authentic user preferences—not favoritism. But the concerns are serious. With LMArena shaping public narratives and investor confidence, any perceived bias or manipulation could undermine its credibility.
Combined with the recent Llama 4 Maverick benchmarking controversy, this study is a stark reminder: not all AI leaderboards are created equal. And in 2025, the real battle might be over who controls the scoreboard.